ایل سی کی سے کیا مراد ہے ؟ پاکستانی کتب خانوں کی ترقی میں اس کا کیا کردار ہے
ایل سی کی سے کیا مراد ہے ؟
تعارف کولمبو پلان :
ایل سی کی سے کیا مراد ہے ، پاکستان میں ایل سی کی کی کیا اہمیت ہے ، ایل سی کی کی رپورٹ کس نے اور کب پیش کی ، کولمبو پلان کیا ہے ، ایل سی کی اور کولمبو پلان کا آپس میں ربط کیا ہے ، پاکستان کی تعلیمی اور معاشی ترقی میں کولمبو پلان کی اہمیت کیا ہے، پاکستان کے کتب خانوں کی ترقی و ترویج میں ایل سی کی کی رپورٹ نے کس قدر اثرات مرتب کیے ، یہ وہ سوالات ہیں جن کا جاننا ایک لائبریری سائنس کے طالب علم کے لیے انتہائی ضروری ہے ۔ایل سی کی یا اس کی پیش کردہ رپورٹ کے متعلق جاننے سے قبل یہ جاننا ضروری ہے کہ ایل سی کی اور کولمبو پلان کیا ہے۔
کولمبو پلان کا قیام
کولمبو پلان بنیادی طور پر ایک معاشی اور معاشرتی فلاحی پورگرام ہے اور یہ کولمبو پلان ایشیاء کی ترقی پذیر ملکوں کی مدد کے لیے ترتیب دیا گیا تھا ۔ یہ ایشیاء کی تاریخ کی سب سے پرانی علاقائی انٹر گورنمنٹل تنظیم ہے جو 1950 میں وجود میں آئی جس کا بنیادی مقصد ایشیائی ممالک کے معاشی اور معاشرتی ترقی کے پروگراموں میں مدد فراہم کرنا تھا ۔ کولمبو پلان سی لون کے مقام کولبمو میں اسی کی بنیاد رکھی گئی اور اسکا باقاعدہ افتتاح 1 جولائی 1951 میں آسٹریلیا ، کینڈا ،بھارت، پاکستان، سری لنکا، یو کے اور نیوزی لینڈ کے اشتراک سے وجود میں آیااب اس میں دیگر کئی ممالک مزید شامل ہو گئے ہیں، جن کی تعداد اب 28 تک پہنچ چکی ہے جن میں نان کامن ویلتھ تنثظیم ،آسیان اور سارک بھی شامل ہیں۔
کولمبو پلان بھارت کے سفارت کار کے ایم پاٹیکر نے برطانوی اور آسٹریلیا کے سفیروں کو کثیر جہتی فنڈ ز کے قیام کی تجویز دی تھی اور اسی تجویز کی روشنی میں 1950 میں برطانوی وزیر خارجہ ارنسٹ ہیون نے سلیون ، کولمبو کے مقام پر دولت مشترکہ کے تمام وزرائے خارجہ کی کانفرنس منعقد ہوئی کی نمائندگی کی تھی۔ اور اس اجلاس میں اس پلان کی منظوری چھ سال کے لیے دی گئی تھی ، بعد میں اس پلان کو کئی مرتبہ مزید آگے بڑھایا گیا۔

پاکستان کے ابتدائی مسائل
کولمبو پلان کے متعلق اتنا ہی بتانا مقصود تھا کیونکہ ایل سے کی ہمارا بنیادی موضوع ہے اور ایل سی کی اسی کولمبو پلان کے تحت ہی پاکستان آیا تھا ۔ پاکستان 1947 میں معرض وجود میں آیا تو اسے ابتدائی کئی مسائل ورثے میں ملے جن میں ایک اہم مسلئہ یہ بھی کہ ہندو لائبریرین بھارت کی جانب ہجرت کر گئے اور جانے سے قبل بہت سے کتب خانوں کا سامان اور کتب بھی ساتھ لے گئے جو نا لے جاسکے تو بقیہ کو تباہ کر گئے یوں پاکستان میں لائبریریوں کو نہ صرف نقصان پنہچا بلکہ لائبریری کا قحط بھی پیدا ہو گیا اور پاکستان کو تعلیمی میدان میں ترقی کرنے کے لیے از سر نو کتب خانوں کی بحالی کا چیلنج تھا ۔ چونکہ 1950 میں ایشئائی ملکوں کے لیے کولمبو پلان وجود میں آ چکا تھا اور اس کے ابتدائی ممبر ممالک میں پاکستان بھی شامل تھا تو حکومت پاکستان کی درخواست پر کولمبو پلان کے پلیٹ فارم سے ایک وفد پاکستان بھیجا گیا جس کا بنیادی مقصد کتب خانوں کے قیام اور ان کی ترقی کے لیے ایک جامع پلان حکومت پاکستان کو مرتب کر کے دینا تھا ۔
مسٹر ایل سی کی
مسٹر ایل سی 1903 میں پیدا ہوئے ، اور شعبہ کتب خانہ کو جوائن کیا اور اپنے دور میں وہ کئی اہم عہدوں پر فائز رہے ۔ جب ان کی وفات ہوئی تو وہ دو عہدوں پر کام کر رہے تھے ۔مسٹر کی دونوں اداروں کی ترقی سے وابستہ تھے۔لیونل کورٹنی سینٹ ایوبن کی، ایم بی ای، بی اے، ایل اے اے، اور ڈپٹی لائبریرین آف دی کامندولت پارلیمانی لائبریری 1947 سے 967، حال ہی میں ایک طویل عرصے کے بعد کیسل ہل میں انتقال کر گئے۔ان کے پسماندگان میں ان کی اہلیہ الزبتھ ہیں، اس کے بچوں اور تین پوتے پوتیوں ہیں۔مسٹر کی، اپنے شعبہ کے اندر بہت سے دوستوں کو جانتے ہیں۔ وہ لائبریری کا پیشہ اور باہر کورنے کے طور پر، ان چھوٹے لیکن پرجوش اور پیشہ ور لائبریرین میں سے ایک تھے جو 1937 میں آسٹریلین انسٹی ٹیوٹ آف لائبریرین بنانے کے لیے اکٹھے ہوئےکے پیشرو تھے، آسٹریلیا کی لائبریری ایسوسی ایشن (1949 میں۔ وہ 1940/41 میں انسٹی ٹیوٹ کے جنرل سکریٹری کے طور پر بہت سرگرم تھے۔ جو اس کی تیسری سالانہ کانفرنس تھی۔ کینبرا میں، اور بعد میں صدر کے طور پر وہ کینبرا برانچ میں اپنی خدمات سر انجام دیتے رہے۔
مسٹر کی طویل، متنوع اور ممتاز ہیں۔لائبریرین شپ میں کیریئر صرف صحیح طریقے سے ایمانداری سے سر انجام دیا جائے تو عزت رتبہ مقام سب ملتا ہے ہو سکتا ہے۔ مسٹر کی جب دولت مشترکہ کی پارلیمانی لائبریری کو ماڈل بنارہے تھے اور اس کے ساتھ لائبریری آف کانگریس میں ، سینیٹرز اور ممبران کی معلوماتی ضروریات کو پورا کرنے ک
ے اپنے بنیادی کام کے علاوہ،کے لیے اور قومی لائبریری کی خدمات کو ترقی دینے کی ذمہ داری بھی لے لی تھی۔ مسٹر کی نے ایک اہم شراکت کی ان قومی خدمات کے لئے، اگرچہ وہبلکہ پارلیمنٹ میں ان کی براہ راست خدمات کے لئے سب سے بہتر یاد کیا جائے گا جہاں ان کا کیریئر تھا (1925 میں اور 1967 میں ختم ہوا۔ ان کی
خدمت لندن میں نیشنل لائبریری کے ساتھ شروع ہوئی 1944 سے 1948 تک اس کا پہلا نمائندہ ہے۔ انہوں نے امریکہ کی طرز پر پہلی آسٹریلین انفورمیشن لائبریری بھی قائم کی۔انہوں نے آسٹریلیا سے متعلق ریکارڈز کی مائیکرو فلمنگ کی نگرانی کی۔نیشنل لائبریری اور پبلک کے درمیان 1945 کے معاہدے کے تحت پیسفک نیو ساؤتھ ویلز کی لائبریری۔
جب یونیسکو کا قیام عمل میں لایا جا رہا تھا پیرس میں آسٹریلوی وفد کے رکن تھے اور بعد میں آسٹریلیا میں لائبریریوں کے لیے یونیسکو کمیٹی کے رکن بنے۔1948 جب مسٹر کی نیشنل لائبریری کے ڈپٹی لائبریرین تھے تو ان کے شاندار تجربہ کی روشنی میں ایشیائی ممالک کے ثقافتی امداد کے فعال پروگرام میں نامزد کیا گیا ۔ ہندوستان، انڈونیشیا اور فلپائن کے لائبریرین کے لیے 1952 کا آسٹریا کا سیمینار اسی کا حصہ تھا۔ یہ مسٹر کی کے مشورے سے 1954/5 میں عمل کیا گیا۔ برما، بھارت، نیپال ، ہندوستان، اور پاکستان کی گورنمنٹ اور لائبریری حکام سے مسٹر کی سب سے ملے.
مسٹر ایل سی کی 1954/55 میں کولمبو پلان کے تحت چھ رکنی وفد کی سربراہی کرتے ہوئے پاکستان تشریف لائے اور پاکستان کے لیے اپنے قیام کے دوران شب روز محنت سے کتب خانوں کے قیام اور ان کی ترقی کے لیے حکومت پاکستان کو ایک جامع رپورٹ1956 میں پیش کی تھی ۔ اس رپورٹ میں نئے کتب خانوں کے قیام کا ایک خوبصور ت جامع پلان تھا جن میں مسٹر ایل سی کی کے مطابق پورے پاکستان مٰں 36 کتب خانے فل فور بنائے جائیں جن میں ایک قومی لائبریری ہو اور دو صوبائی سطح پر لائبریریاں بنائی جائیں ۔ اس رپورٹ میں یہ بھی کہا گیا اور تجویز پیش کی گئی کہ پاکستان میں موجود 20 کالجز میں اور ایک خصوصی لائبریری فوری طور پر تیار کی جائے ۔ یہ 1956 میں اس وقت پاکستان کے لیے ایک شاندار رپورٹ تھی اور ایک جامع پلان تھا اگر اس پر اس وقت عمل ہوتا تو پاکستان تعلیمی میدان میں آج دنیا کا مقابلہ کر رہا ہوتا مگر اس پلان کو سرد خانے میں ردی کی ٹوکری میں ڈال کر موت مر دیا گیا۔ بعد میں اسی رپورٹ کی روشنی میں 1959 میں حکومت کو خیال آیا تو ایک نیا پلان ترتیب دیا گیا جس کے مطابق ہر صوبے میں صوبائی سطح پر ایک لائبریری ، ڈویژن ، ضلع، تحصیل اور سب تحصیل سطح پر کتب خانوں کی تجویز دی گئی مگر اس پر کس حد تک عمل ہوا ا س سے آپ سب واقف ہیں ۔
1961 میں مسٹر کی مکمل وقت پر واپس آئےپارلیمنٹ کی خدمت جو ان کی پہلی محبت تھی۔اپنی لائبریرین شپ کیڈٹشپ میں گریجوائیشن میلبورن یونیورسٹی سے مکمل کی۔اورمسٹر کی قانون سازی حوالہ جاتی خدمات کے بانی تصور کیے جاتے ہیں۔انہوں نے یہ کام اس وقت کیا جب پارلمیانی لائبریری سروس صرف کتابیں پڑھنے تک محدود یہ تھی۔1966 میں انہوں نے اسٹیبلشمنٹ لیجسلیٹوریسرچ سروس میں حصہ لیا انکی کی بہترین خدمات میں سے آسٹریلیا میں یہ ان کی نمایاں اور منفرد سروس تھی جس کے وہ بانی تھے۔1967 میں ان کی ریٹائرمنٹ کے موقع پر ان کا ایم بی ای کے ایوارڈ سے نوازا گیا۔ مسٹر ایل سی کیا آسٹریلیا کی لائبریرین شپ کی تاریخ میں سب سے نمایاں ہیں۔ ان کی وفات سڈنی میں بروز جمعہ 26 نومبر 1982 کو ہوئی۔
۔
ایل سی کی سے کیا مراد ہے ؟ پاکستانی کتب خانوں کی ترقی میں اس کا کیا کردار ہے Read More »







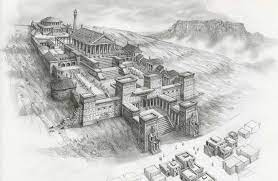


 According to ancient accounts, the library was said to have had several different buildings or wings, each dedicated to different subjects or collections. However, it is not clear how large each of these buildings was or how much land they occupied.
According to ancient accounts, the library was said to have had several different buildings or wings, each dedicated to different subjects or collections. However, it is not clear how large each of these buildings was or how much land they occupied.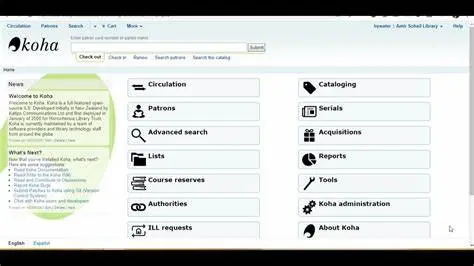
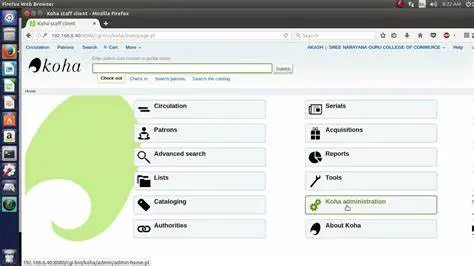 manage the system. Additionally, Koha is actively developed and supported by a global network of volunteer developers and contributors, which ensures that the software is continuously updated and improved.
manage the system. Additionally, Koha is actively developed and supported by a global network of volunteer developers and contributors, which ensures that the software is continuously updated and improved.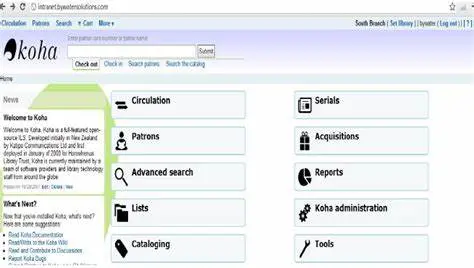

 designed to be flexible and customizable, it can be challenging for libraries to make significant changes to the software without the help of a developer.
designed to be flexible and customizable, it can be challenging for libraries to make significant changes to the software without the help of a developer.